SQL for Data Science
An overview of SQL for data science.

At the core of Data Science is the Data. To perform any analysis, derive insights, and perform predictive modeling, you need data. And most of the data is stored in databases.
Even in this day and age, almost 90% of the data is in tabular format and hence structured format, even though many modern industries have geared their product to deal with unstructured data formats.
What is SQL?
SQL stands for Structured Query Language. It lets you access and manipulate databases. execute queries against a database, retrieve data from a database, insert/update/delete records in a database, create new databases or new tables in an existing database, and much more.
Importance of SQL in Data Science
As we saw, most of the data stored in databases are structured and use a Relational Database Management System. This is where Structured Query Language (SQL) comes into the picture. It helps us define, modify, extract and control the required data from the databases for further processing.
Hence the role of a Data Scientist demands knowledge of SQL. In fact, most of the interviews for the role of a Data Scientist include questions on SQL queries.
Many database platforms are modeled after SQL. This is because it has become a standard for many database systems. As a matter of fact, modern big data systems like Hadoop and Spark make use of SQL for maintaining relational database systems and processing structured data.
SQL Skills required for Data Science
1. Knowledge of the Relational Database Model
A Relational Database Model System (RDBMS) is the primary and foremost necessary skill for a Data Scientist. In order to store structured data, one must know RDBMS concepts like schema diagrams, types of relations that can exist between tables, etc. You can then access, retrieve and manipulate the data through SQL.
2. Knowledge of the SQL commands
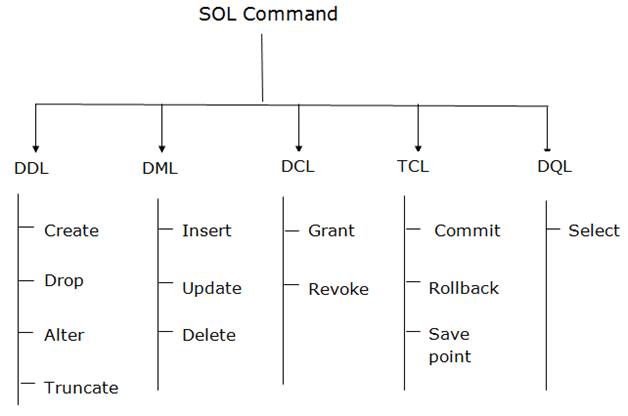
A Data Scientist should know the following SQL commands –
- Data Definition Language (DQL)
- Data Manipulation Language (DML)
- Data Query Language (DQL)
- Data Control Language (DCL)
- Transaction Control Language (TCL)
3. Primary & Foreign Key
A primary key represents unique values in a database. With the help of primary keys, we are able to distinguish between each line and record from the database. A Foreign Key, on the other hand, is used to connect two tables together.
4. Null Values
Null is used to represent a missing value. A field that contains a Null value is blank in a table. Note, however, that a Null value is different than a zero value or a field that contains blank spaces.
5. Creating Tables
Data Science makes use of organized relational tables, and therefore, it is necessary to know how to create tables in SQL. Based on the business needs and your understanding of the relationship between various tables, you can go about designing and creating the tables.
6. Joins and Unions
Table joins are the most important concepts of relational databases that a data scientist must know. There are two types of joins – Inner Join and Outer Join. Outer join is further divided into Left, Right, Full joins, etc. Apart from these, Union and Union All are also used to combine the result set from two or more SELECT commands.
7. SubQuery
A subquery is a nested query that is embedded in another query. There are four important subqueries in SQL – SELECT, INSERT, UPDATE, and DELETE. It will return the information to the primary query.
8. Group By operations
Many a time, the data you are looking for can’t be gleaned by using simple select statements. It needs to be grouped into various categories so that relevant data can be fetched. Group by command allows you to do exactly this.
Concluding
We saw how important a skill SQL is for the role of a data Scientist and the various facets of SQL he/she should be familiar with. There are various online SQL courses and platforms where you can test your skills at SQL queries that you can take right away and begin the journey.
IIT-Madras CCE & Pixeltests Artificial Intelligence Certification
Secrets to secure 50 lac/year jobs
4.8+ Trust Pilot; Mentored Over 36000+ working professionals